
Leveraging SQLMesh for Domain-Driven Development Across Environments
A deep dive into supporting analytics along a DDD approach


Introduction
Domain-Driven Development (DDD) has been trending for several years, and you've likely seen it applied in data engineering through concepts like data mesh. For those unfamiliar with these terms, data mesh is an approach to creating domain-specific silos in data platforms to promote scalability, autonomy, and improved data quality across an organization through dataset ownership. In practice, this means most datasets are private by default, with only designated datasets accessible to other teams. It's similar to wrapping a relational database management system (RDBMS) into a microservice and exposing features through APIs.
When teams work autonomously, they often become responsible for designing their own data models. Many of these models are built using relational databases where reference data resides. Using this schema, teams can denormalize the data model for use in analytics scenarios. However, this process often occurs in different environments, potentially duplicating logic that can diverge downstream.
An example
Let's examine a single example to better understand this concept:
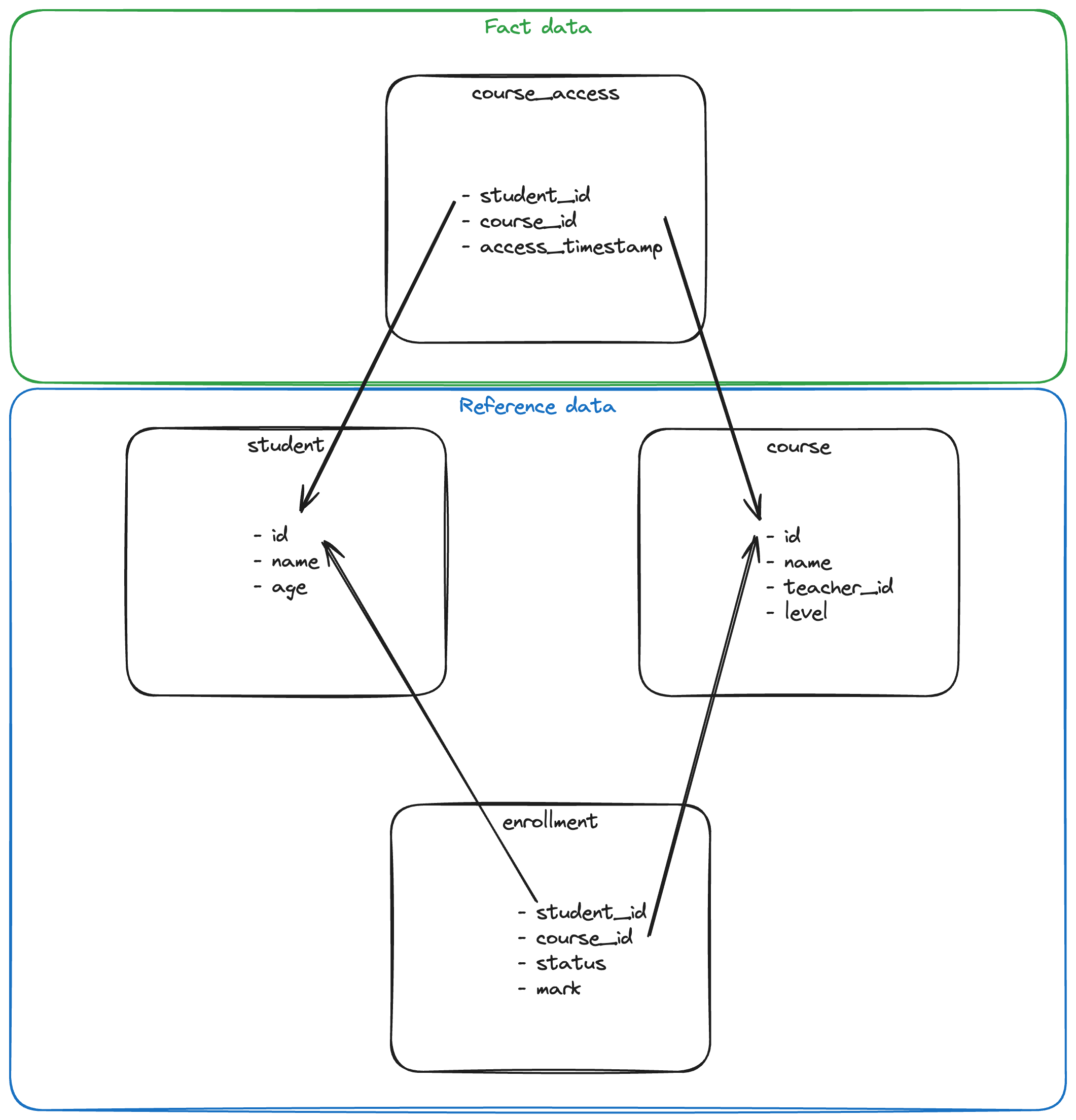
Assume the team owning this student reference data wants to expose a dataset of the top 3 performers per course. The query (with some fixtures) to accomplish this is relatively straightforward:
CREATE TABLE top_3_performers_per_course AS (
WITH student AS (
SELECT 1 as id, 'john' as name UNION ALL
SELECT 2 as id, 'henry' as name UNION ALL
SELECT 3 as id, 'bradley' as name UNION ALL
SELECT 4 as id, 'thomas' as name UNION ALL
SELECT 5 as id, 'jack' as name
),
enrollment AS (
SELECT 1 as student_id, 50 as course_id, 10 as mark UNION ALL
SELECT 2 as student_id, 50 as course_id, 15 as mark UNION ALL
SELECT 3 as student_id, 50 as course_id, 11 as mark UNION ALL
SELECT 4 as student_id, 50 as course_id, 10 as mark UNION ALL
SELECT 5 as student_id, 50 as course_id, 9 as mark
),
course AS (
SELECT 50 as id, 'history' as name
)
SELECT s.id as student_id, s.name student_name, c.id as course_id, c.name as course_name,
RANK() OVER (partition by course_id order by mark desc) rank_in_course
FROM student s
JOIN enrollment e ON s.id = e.student_id
JOIN course c ON c.id = e.course_id
QUALIFY rank_in_course <= 3
);Through this query, we've implicitly decided how to handle cases where two (or more) students tie for third place. This could be a good reason to encapsulate that logic and prevent the second team from needing to replicate it if required.
Now, let's say the second team wants to analyze the correlation between attendance statistics and course scores. However, access data is fed into the data warehouse (e.g., BigQuery), while the reference data tables are in a PostgreSQL database owned by the first ("reference data") team. How should the "analytics" team access the reference data?
Ways to Access Reference Data in Analytics Contexts
There are various methods to provide access to reference data within a data warehouse. Let's examine some of them and compare their pros and cons:
No strategy is a silver bullet, so you may need to choose the most appropriate approach or combination of approaches to meet your specific needs.
The question remains: what should you synchronize in the data warehouse? The reference tables or the results of complex logic? Considering our previous example, would you copy the student, course, and teacher tables? What about the top_3_performers_per_course view?
Again, it depends:
If using federated queries, you can probably read directly from the
top_3_performers_per_courseview. However, if you're using a PostgreSQL database, federated queries from BigQuery are not currently supported.If using batch copies, you can sync the
top_3_performers_per_courseview, though if there are many views, you may end up duplicating a lot of data compared to having the reference tables with matching views in BigQuery.If using CDC replication, you have no choice but to copy the actual reference tables.
So, what if we copy the reference tables? Does this mean we have to duplicate the logic written in PostgreSQL in BigQuery? 🤯
SQLMesh to the Rescue
Duplicating logic across multiple SQL dialects, projects, and tools can be troublesome and raises several questions:
How do you ensure consistent definitions across environments?
Isn't it time-consuming for developers to convert and test definitions in each environment?
What tools should be used to create, test, and deploy views in all these environments?
Perhaps a single tool can meet all our needs for this use case: SQLMesh.
How?
SQLMesh offers great features for working across multiple environments:
It supports PostgreSQL, Iceberg (through Athena or Spark), and BigQuery
It can transpile SQL across dialects from these engines
It can run tests in a different engine than the target one (e.g., using DuckDB while targeting any of the mentioned engines)
Assuming we use CDC replication, we could have an architecture like this:
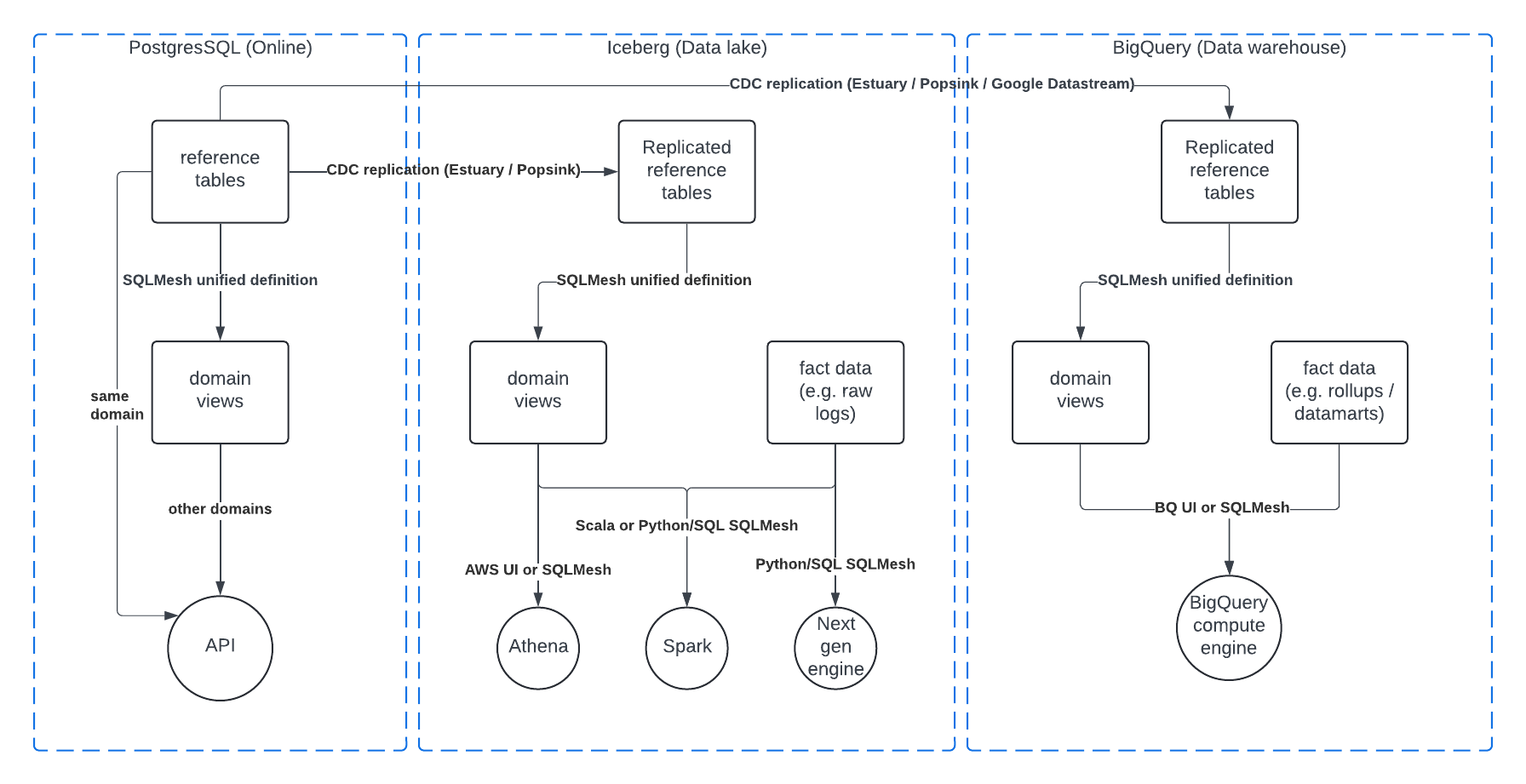
Example
Building an example is fairly straightforward. I've created a small GitHub repository that showcases how it works with an even simpler case:
https://github.com/Kayrnt/sqlmesh_multi_engine_views
You can follow the instructions and run it yourself to see how easy it is to use.
Strengths
This approach has many advantages. Let's summarize:
Leveraging CDC in the data lake and data warehouse brings all the previously mentioned advantages (near real-time data synchronization, efficiency, auditing, etc.)
Many data sources can now be synced with CDC using third-party tools (like Estuary or Popsink), but there are open-source alternatives based on Debezium
Offering a single view definition in one SQL language leads to a great developer experience by preventing divergence between view definitions
SQLMesh's multi-project support enables bridging these view definitions and data transformations in a single lineage (even at the column level), making it easier for developers to deal with breaking changes
Creating a large number of distinct views to address multiple needs doesn't require copying more data to target environments
Thanks to data lake support, this architecture can support a wide range of engines such as single-node engines (DuckDB, Polars), distributed computing engines (Trino, Spark), or even GPU analytics (Theseus, SQream)
Weaknesses
This strategy is not a silver bullet either. Let's recap what you need to be careful about:
Leveraging CDC also comes with the challenges mentioned (complexity, resiliency, high volumes)
There's still little experience with some of these new platforms, so you might encounter issues with advanced use cases or edge cases that may not be well documented
SQL transpilation is still niche, and although there are many tests, is it reliable enough to be used without reviewing each conversion?
A Better Alternative?
Views are great as they are widely available in many engines and often stored in the system, allowing any framework to access them. However, views don't work well with fields that are not additive.
Another approach worth considering is semantic layers. Semantic layers are similar to views but can go further regarding predicate pushdown or non-additive dimensions. However, these systems are often complex and not well integrated with every framework. For instance, dbt integrates MetricFlow, its semantic layer, but it's not compatible with SQLMesh, which has its own metrics system. Some semantic layers like MetricFlow or Cube provide JDBC & GraphQL APIs, making them great for connecting more platforms. While you would benefit from full lineage, it's a good way to make it more "interoperable."
SQLMesh may not be there yet, but I wouldn't be surprised to see it coming in their paid offering. In the meantime, views are an interesting trade-off worth considering!
Summing up
Managing reference data across multiple environments in a domain-driven development context presents unique challenges, but also opportunities for streamlined data management. We've explored various approaches to accessing reference data in analytics contexts, each with its own set of pros and cons.
SQLMesh emerges as a powerful tool that can address many of the challenges associated with maintaining consistent view definitions across different database engines. Its ability to transpile SQL across dialects, support multiple environments, and provide a unified lineage view makes it an attractive solution for organizations dealing with complex data architectures.
However, it's important to remember that no single approach is perfect. While SQLMesh offers significant advantages, it also comes with its own set of considerations, such as the complexity of CDC implementation and the relative novelty of SQL transpilation at scale.
As data architectures continue to evolve, we may see further developments in this space. Semantic layers, for instance, offer an intriguing alternative to views, providing more flexibility in handling non-additive dimensions and potentially offering better integration across different platforms.
Ultimately, the choice of approach will depend on your specific use case, the scale of your data operations, and your organization's technical capabilities. Whether you opt for SQLMesh, explore semantic layers, or stick with traditional methods, the key is to prioritize data consistency, accessibility, and maintainability across your entire data ecosystem.
Next
As we witness significant investments in data storage, management, and cataloging on one side, and promising new computing platforms on the other, there's no doubt that this kind of "bridge" technology is poised to flourish in the coming years.
I'm very curious to hear about your experiences if you've considered or implemented a similar approach. Was it successful? Please share your thoughts and insights in the comments below! 💡
🎁 If this article was of interest, you might want to have a look at BQ Booster, a platform I’m building to help BigQuery users improve their day-to-day.
Also I’m building a dbt package dbt-bigquery-monitoring to help tracking compute & storage costs across your GCP projects and identify your biggest consumers and opportunity for cost reductions. Feel free to give it a go!