
Is SQLMesh the dbt Core 2.0? A foot in the door.
dbt dominates the transformation on SQL workload but is it still going to be the king in 2024 and beyond? What does it take to move from dbt to SQLMesh?

In this article, we’ll see why SQLMesh is interesting as a dbt alternative, how it compares to dbt and how the dbt project compatibility can be leveraged to try it out.
Introduction
dbt undeniably changed the day to day from a lot of data engineering jobs over the past years. Some might have skipped it (especially if you’ve been working with Scala Spark or Streaming platforms) but it became the defacto tool to manage your transformation using the “Modern Data Stack”. dbt has been mostly leading the way for the last 3 years without much credible alternatives.
I jumped on the “hype train” in September 2020 seeing it as an open source replacement for my company inhouse equivalent. It brought new features and concepts to the table that we didn’t have. Yet it lacked few ones: it’s how I started to contribute to the projects as some of them were definitely blockers to use it. Those were mostly targeted at BigQuery as it’s the data warehouse I’m working with.
Fast forward, it’s been close to 3 years that I’ve put dbt-core in production. it enabled to scale human-wise our data warehouse pipelines effectively and be more productive. It’s a win overall.
Why looking elsewhere then?
As our dbt project matured, I started to hit some of its limits here and there. I managed to workaround most of them but they are often tied to the software design. They’re often well known but not so easy to deal with. Some of them require a lot of changes but are not prioritized because they are a lot of other topics that are more valuable to the dbt Labs customers. I’ve been using the OSS core because dbt Cloud doesn’t offer enough value and flexibility to my engineering heavy company (I don’t feel like we’re targeted customers).
Then I always wondered is there a dbt alternative that target the kind of scale I’m working at? A tool designed to work on data warehouse at Petabytes scale efficiently while empowering their users with best in class software engineering practices?
A new contender
I love to keep up with the data engineering space so I somehow ended reading about SQLMesh 1 year ago and deemed the project as promising but I couldn’t see value back then.
I spent a good chunk of 2023 playing around DuckDB/MotherDuck and even built a mysql FDW for it. I’ve tried quite a few use cases around it but hardly found anything worth using in production at my scale (yet).
Reading about SQLMesh related posts and documentation, few features started to stand out:
Creating proper unit tests, while it is not natively supported on dbt
It should become available in dbt in 1.8
Using a SQL language (eg DuckDB) and run it in another platform (eg BigQuery) thanks to sqlglot transpilation
Which allows for running and validating your SQL on DuckDB locally for development purpose
Offering dbt project compatibility
Supporting Python macros
Building native incremental model per period support with backfilling
Enabling cost efficient model changes through a view + physical table layer and breaking changes detection
Display the column level lineage
available on dbt Cloud only
Provide a CI/CD bot
available on dbt Cloud only
Support for multi project
available on dbt Cloud only
From dbt to SQLMesh?
A lot of great promises on the paper, but are they working as intended? In the rest of the article, we’ll have a look at how SQLMesh deals with a dbt project.
The scope of this article is to be able to use all previously quoted features along maintaining dbt project structure compatibility.
For that we’ll leverage an example dbt project: we’ll fork the dbt_jaffle_shop_duckdb and add some more models to test more features.
Here’s the modifications, we add to that dbt project:
Add the minimum changes to setup SQLMesh
`start: Jan 1 2000` in dbt_project.yml and config.py with duckdb state connection
Add some advanced SQL functions usage
Add SQL UDFs
Add unit tests
First let’s have a look at how dbt project concepts translates into SQLMesh concepts.
Configuration
Engines
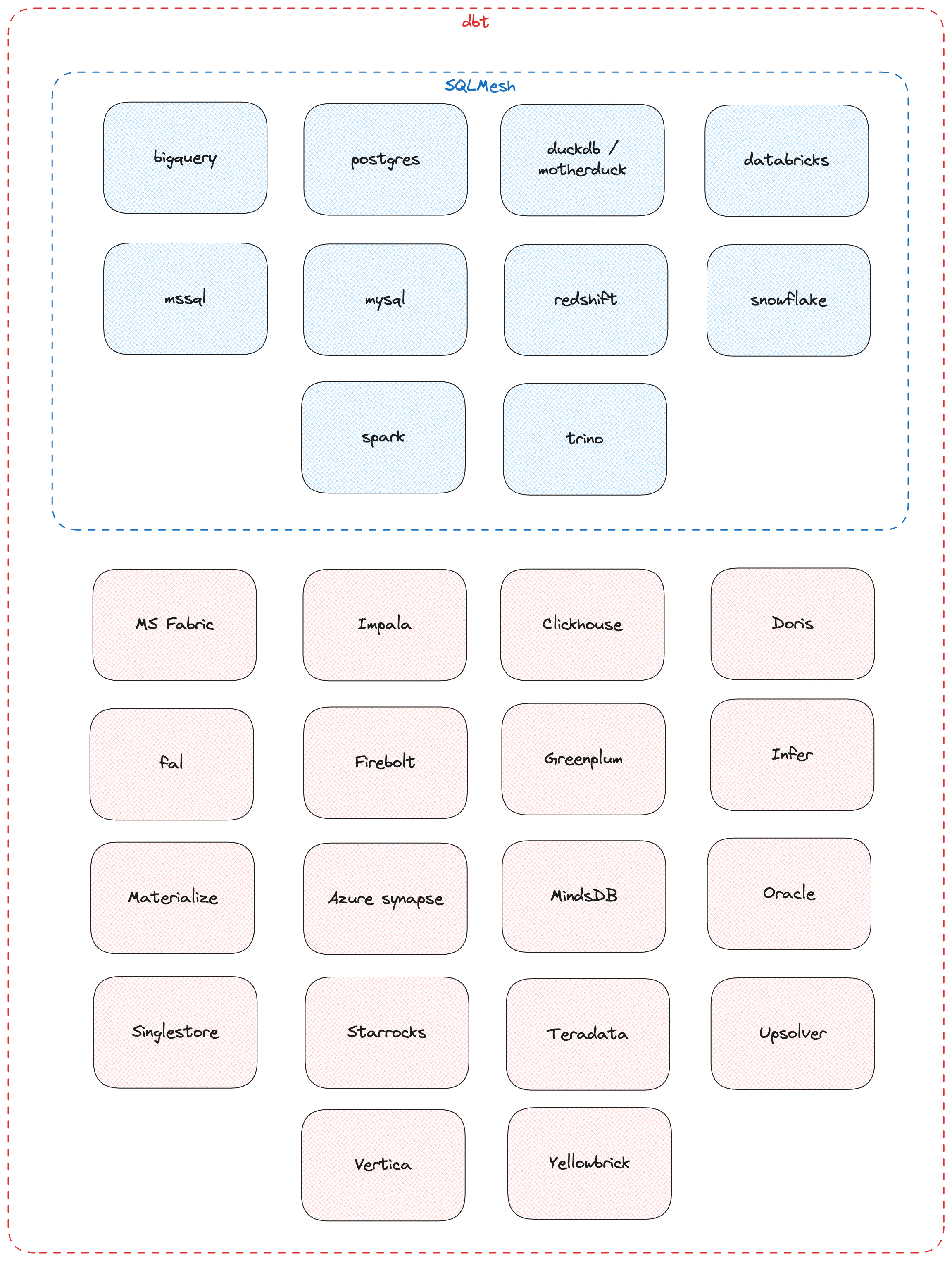
Thanks to his longer history and large community, dbt has a large choice of supported engines. Yet SQLMesh team did a great job at supporting a good chunk of top databases/data warehouses on the market. There’s no doubt that the team is eager for external contributions to support more of them.
Profiles vs connection & environment
In dbt, profile targets are all you need to define where data is being written. SQLMesh brings another level of abstraction at configuration level as the connection (“gateway”) is distinct of the environment. Then it’s even different at materialization level: the actual data is set in a dedicated dataset to store physical tables leveraging an hash that match your model “version”. The data is exposed to consumers using views in the configured dataset.
For non prod environment, the environment name is suffixed to the dataset name (and creates it if it doesn’t exist).
Here what it looks like:

Using dbt integration, you can’t really set up an environment to use with a different gateway so dataset acts as a proxy. Yet if you’d like to have a distinct one from your coworkers, you’d likely need to rely on environment variables use a distinct configuration to have a runtime variable that will shift the value to what you need.
It can feel a bit awkward as SQLMesh workflow isn’t fully aligned with dbt approach but somehow it works fairly well. If you want to you can change the physical tables location and name as well with SQLMesh configuration.
However if you have an existing dbt project in production, you’re going to run into a problem: the SQLMesh approach uses views where dbt will materialize tables directly. Then it means that it will require to migrate from one tool to the next one as you would have failure such as:
Error: Failed processing SnapshotId<"my_gcp_project"."my_dataset"."customers": 2475846015>. 400 my_gcp_project:my_gcp_project.customers is not allowed for this operation because it is currently a TABLE.; reason: invalid, message: my_gcp_project:my_gcp_project.customers is not allowed for this operation because it is currently a TABLE.Also the “view layer” approach is definitely smart until it runs into the weaknesses of the underlying system. With BigQuery, if you are using views, you usually don’t lose the underlying optimizations regarding predicate pushdowns on partitioning and clustering. However if you need to access metadata columns such _PARTITIONTIME on ingestion time partitioning tables, it wouldn’t work.
Variables
There's 2 ways to configure variables with dbt:
Declare them in dbt_project.yml
Declare them using
--varsat command line invocation
SQLMesh doesn’t provide a variable support on its own. SQLMesh has recently added global variable support. You can access variables in the configuration to define getaways and environments. Also you can use @DEF macro from SQLMesh to create model local variables. SQLMesh team made a good job at supporting dbt variables with the integration.
To the point, variables field can be set up using config.py to define them for dbt var jinja function. SQLMesh team even suggests to use that approach as a proxy for runtime variables. It makes sense that SQLMesh doesn't support any --vars or equivalent command line option on its commands but I'd say it's rather inconvenient way to do so.
I'd suggest another path as suggesting to use environment variables based variables and then change those environment variables at runtime as I feel like it's often more common to change to tweak the environment variables than the code (at least for people that would using the dbt command line option anyway).
Of course, it doesn't solve the actual problem with proper runtime variables for templating (which is for me a major caveat from dbt if you want to build report templates). I’m not surprised they don’t as neither SQLMesh nor dbt are built for that. Yet SQLMesh brought some interesting “basics” with predefined runtime variables: start date, end date and run date.
Yet, allowing to setup user defined ones would be a step ahead in providing runnable templates without custom tools or “hacks”. It’s doable in dbt but it will always recompile the queries because the variables can change the DAG.
Models
Most dbt resources types are supported (models, seeds, sources, snapshots) and most materializations (table, view, incremental, ephemeral) have their equivalent in SQLMesh.
Indeed the types can be pretty much matched one by one:

Which left us with few cases that are not supported (yet?):
Custom materializations (yours or through packages)
Standard materializations that have been modified using macro overrides
Since SQLMesh uses its own implementation to support those as it “imports” dbt models under its own representations
Adapter specific materialization
For instance, SQLMesh doesn’t support `time_ingestion_partitioning` or `copy_partitions` options which could be deal breaker for some dbt users.
exposures
analyses
Overall it’s hardly a blocker for most users but in my case, it wouldn’t work for models that are using dbt ingestion time partitioning option on BigQuery and since I’ve a good amount of those in production, it doesn’t seem like a viable solution. However in the scope of the tested project, it’s not an issue.
For the time being, SQLMesh and dbt models can’t be used in the same project directly but you can look into creating a SQLMesh multi project where the first project is using the dbt integration while the latter is sqlmesh native1.
UDFs are supported through sql_header like on dbt. On BigQuery, SQLMesh is leveraging sessions to keep temporary functions in the scope (smart one!).
One thing I missed is that I couldn’t both use dbt models and SQLMesh models in the same project but as quoted it might be smarter to have a multi project architecture with 1 dbt only and 1 SQLMesh only.
Tests
Both platforms provide 2 types of tests:
data tests / audits to validate properties on actual data on resulting outputs of the models
unit tests to validate the logic of a model using given rows and expected rows

audit
dbt data tests have been there for a while and are widely used by dbt users. Any dbt test should work even those from dbt_utils like accepted_range test.
unit tests
Though unit tests are very new on the dbt end: they are meant to be released in dbt 1.8 while it’s been one of the core feature of SQLMesh since the beginning. So far, SQLMesh doesn’t support dbt unit tests through its integration yet.
In the meantime, SQLMesh team allows to use its native unit tests on dbt models which definitions are actually very close to the form from upcoming dbt unit tests.
For instance, let’s test the accepted range for customer id based on the provided seed in the jaffle shop project. It just requires us to create a YML file in /tests (like a regular dbt test) with following content:
customers_test:
model: main.customers
inputs:
main.stg_customers:
rows:
- customer_id: 1
main.stg_orders:
rows:
- order_id: 1
customer_id: 1
main.stg_payments:
rows:
- payment_id: 1
order_id: 1
amount: 100
outputs:
query:
rows:
- customer_id: 1
number_of_orders: 1
customer_lifetime_value: 100It’s very simple and works like a charm. The single pain point I encountered is that the model name is “stained” by the environment in dbt integration: as you can see I have to prefix with “main” (the schema) when I’m writing the SQLMesh test. Then it means that if you have DuckDB test environment and another BigQuery production one… you need to sync the “schema” on both else it won’t work with the same config “automated” config. We’ll get back to why I’m speaking about using 2 engines (one for test and one for production later on).
Workflow
SQLMesh really shines when it comes to workflows. In that part we’ll see how it can enhance productivity and save on computing costs compared to dbt. I’ll go into details in the matching development cycles.
Let’s assume we want to build that kind of workflow:

In presented case the developer experience is going to be aligned with the CI one.
Developer
Let’s start with the developer workflow. When using dbt, you would create your sources and models. Then you would extract some sample data to run your models either by copying your data in your dev/staging environment or using a LIMIT on the original dataset.
SQLMesh is going to provide some value to move and especially safer: first, as the models are parsed using sqlglot, any invalid SQL is caught early, even before running it on your target engine. For BigQuery users, it’s similar to the dry run look and feel that you have on the BQ UI.
From the UI, you can access to the lineage which is very convenient to visualize a data pipeline workflow. Then you’ll start with the “evaluate” part where you can pick the runtime variables and with a limit so that you can test your changes on a sample. For some reason, the limit is not shown in the query tab but it’s applied at the last select level so it might not be much faster to run the whole query but at least faster to read from the engine to display in the Data preview tab.

Then you can use plan command which is practically a diff between your current state and deployed state. It’s similar to a defer with a state where state is stored in a state connection. It can be stored the same engine as the target one but it’s recommended to use an online such as Postgres (or equivalent). For the developer experience, a local duckDB is likely the most convenient approach (especially if you have small seeds and you can run required models in a timely manner).
Though the UI lacks it for the time being, you can use the —select-model option on plan to run a subset of your project in non prod environment. It simplifies development over large projects as you don’t have to run changes of all models on your environment.
Overall the UI is useful and easy to work with. It’s not as powerful as an IDE but yet it’s simpler for people to use it and available for free. We might see an extension like dbt Power User pop some day but it’s clearly not a deal breaker.
model change detection
One major change compared to dbt is that SQLMesh actually parses the model content to be able to determine if we make a logic change or just a refactoring:
First we are making a logical change (eg change a field from
MIN(amount)toMAX(amount)) to model_1. Then SQLMesh will infer a signature (in the chart below, 123) and update as the semantic is different: it moves from 123 to 124 in the example.Second we are making a refactoring change (eg change the casing of your SQL from min to MIN) to model_2. SQLMesh detects that the changes don’t create a new signature as it’s the “same” request. Of course, it can’t detect advanced refactoring for the being but it’s still a nice feature.

Then it allows to run only the actual logic changes on your next plan. It’s a time saver if you have format changes and especially when it impacts macros that are used in a lot of models. Also it can compute the second version in the background so that if an audit fails, it keeps previous version. Also if for any reason, you need to rollback, you can do so without added cost as it’s just about refreshing the model view definition for SQLMesh. SQLMesh has a whole explanation over the benefits of that approach called virtual data environments which is at core of the tool.
Testing
There’s a lot to say about testing! As presented before, besides supporting dbt tests, SQLMesh is doing great at unit testing. It’s likely a practice that’s not widespread because there’s no “easy path” (yet) with dbt.
SQLMesh has one feature that I love for unit testing: generating fixtures from actual input/output tables. It saves a lot of boilerplate work that is time consuming which is also one of the reasons that users might not test as much as they should want. It’s fairly simple to achieve as it requires to run one command create_test with the model and one select statement for every referenced model. So for our example project, it would look like this:
sqlmesh create_test dbt_cou.customers \
--query dbt_cou.stg_customers "SELECT * FROM dbt_cou.stg_customers LIMIT 3" \
--query dbt_cou.stg_orders "SELECT * FROM dbt_cou.stg_orders LIMIT 3" \
--query dbt_cou.stg_payments "SELECT * FROM dbt_cou.stg_payments LIMIT 3"The related unit test is then written to a YAML and it is ready to use on your next plan.
SQLMesh is way further on the testing than dbt as you can use a different engine for testing. The most common combination is to leverage DuckDB as a proxy to your commercial data warehouse. To achieve that it’s again, thanks to the actual parsing that can understand a BigQuery query and convert it to DuckDB dialect… or the other way around depending on your preference. Of course, the limit is how compatible both dialects are since in some cases engines have their own unique features. Yet it’s accessible to the dbt integration without hurdles.
Continuous integration
One of the assets of dbt is definitely the ability to build a slim CI (only run/test on what changed). Yet it can be complex to set it up properly if you’re doing by yourself using dbt Core. I wrote an article about the setup I did for dbt for that use case if you want to compare.
There are multiple kinds of continous integration workflows so we’ll focus on one of them. As SQLMesh built a specific integration for Github actions, we’ll leverage it along that following scenario and expectations:
The developer creates a change, pushes it to a branch on Github and open a pull request
The CI bot will validate the change
It should check that the code change syntax is valid and didn’t break the model and downstream ones
It should check that the related model tests are successful
On dbt, we can use defer feature combined with @ selector on a dbt build. On SQLMesh, it’s not directly available as a single command, it’s a combination of multiple commands such as plan, test, diff and audit. Though it might be a slightly complex to orchestrate by yourself, SQLMesh offers a Github CI/CD bot that’s pretty easy to set up! It required very few changes to adapt the example to install & configure dbt to be able to run it on my test project.
If you’re using another platform (eg Gitlab), you’re out of luck for the time being. Looking at the code, it feels like there’s definitely room to adapt the code for another platform than Github but it would take some effort.
There’s some room for improvements (eg showing more details about the changes) but I guess we will see them in an enterprise version of the bot.
Continuous delivery and production
This part is somehow linked to the former one as the Github CI bot is also a CD bot! It can operate deployments which is very handy! Indeed it can take care of backfilling incremental models and creating table/views on changes merge.
In the case of SQLMesh workflow, both continuous delivery and production are linked. Let’s list the different cases:
A developer created a new model, the pull request is merged and then the CD bot will run the new model (and backfill it if necessary). That’s the simplest case.
A developer is modifying an existing model with a large history, then the CD bot will create the physical model and backfill if set up to. There’s interesting features like default_pr_start along start parameter in models to limit the backfill which very useful, especially when you’re using partition expiration.
The model and its downstream models will be recomputed depending on if the change is forward only (which can be defined at model level or at runtime level but not in the current Github CD workflow)A developer deletes a model, then the CD bot will delete the view from that model (but not the physical tables apparently) which is pretty handy clean up your production environment.
As you can see it’s great. Yet there might be corner cases where your deployment and related plan can go wrong and then… it can impact your production: during the deployment, SQLMesh is “locking” its runtime tables which means your incremental workload job (which is basically have a sqlmesh run CRON running on an orchestrator) won’t run again till the plan is done. You can fix the state by running again a fixed plan but it might stale your production in the meantime. So one solution is to isolate your workloads through multi-project support as you can’t use model selection on prod environment (and I’m not sure why).
Incremental by time models
These models are one of those that present the most advantages on SQLMesh compared to dbt: SQLMesh offers to batch the incremental processing which is really useful when you operate at scale. Of course, it requires to add a dedicate jinja and config properties but it’s very accessible and really a missing feature to dbt.
SQLMesh project development and support
It wouldn’t be fair to write an article about SQLMesh without highlighting the engagement and dedication of Tobiko data team to help me to work on this proof of concept.
To give more pragmatical examples, here’s the list of changes/fixes that were more (or less) related to that article and my own tests:
All of those happened in about 1,5 months and it’s clearly just a part of everything they’ve work on. Releases pace is “crazy” as they had like 30 versions in the meantime (almost 1 release every 2 days for more than a year).
The support on their Slack is very active and the team is very helpful.
So I’d like to thank them for their effort and assistance! Especially Toby Mao, George Sittas, Chris Rericha and Iaroslav.
Conclusion
As you can see SQLMesh has a lot of cool features and deal with some of dbt caveats. dbt has been setting strong standards on the form but the SQLMesh goes further with a more opinionated workflow thanks to its diff by design and state management.
It’s no wonder that dbt is compared to jQuery while SQLMesh has some Terraform look and feel. dbt has an easy to use approach and it’s straightforward to understand even for contributors with little data engineering background. That’s likely one of the reason we see so much adoption.
SQLMesh bridges some of dbt’s shortcoming at the expense of more concepts and abstractions. It provides a lot of capacities and meets gaps that really matters for engineering organizations and especially those that operates a TB+ scale.
SQLMesh dbt integration is great idea on the paper but it revealed itself as a frustrating option if you want to use it in production: it’s not possible to switch to SQLMesh on an existing dbt production environment as is. Indeed it will recreate your full environment with the sqlmesh concepts which might work out on smaller projects but hardly on big ones. Then I feel like it’s interesting to do a proof of concept of the tool but I was to use it in production, I’d definitely migrate to fully to a native SQLMesh project to leverage all the capacities that aren’t available.
For the time being, there’s no way to migrate automatically but I wouldn’t be surprised that’s on the radar of SQLMesh team as they already do it internally to support the dbt integration.
SQLMesh still has few rough edges. It’s younger, I ran into few bugs (but it was way more stable than I expected) and it’s not a 100% superset of dbt. If it keeps its trajectory, I wouldn’t be surprised to it becoming a strong competitor to dbt though the targeted audiences are different in my opinion: SQLMesh will likely appeal a lot more data engineers than data analysts.
My takeaway
If you’re working for a company where tech is central to your business, your datasets are beyond TB+ scale and you have a seasoned data team, SQLMesh could really fit your needs!
Also if you’re all in dbt Core and you’re hitting limits, then keep an eye on SQLMesh or even give it a try.
In all other cases, it might be easier to stick to dbt Cloud (or dbt Core) for the time being.
Since I’m using few features that are not available on SQLMesh in my day to day work, I don’t expect it to become my main driver in the short term but I’m planning to use it to improve my developer experience on dbt (e.g. for column level lineage and unit test creation).
What about you?
🎁 If this article was of interest, you might want to have a look at BQ Booster, a platform I’m building to help BigQuery users improve their day-to-day.
Also I’m building a dbt package dbt-bigquery-monitoring to help tracking compute & storage costs across your GCP projects and identify your biggest consumers and opportunity for cost reductions. Feel free to give it a go!
And don’t hesitate to share the post!
This method is not yet supported at the time of writing but it’s in the backlog
What's the "bigquery sql compute"? Do you mean scheduled queries?
Of course, you can do it without sqlmesh/dbt, you can stitch some shell or python scripts to do it.
You just don't get everything it brings.
A view != a scheduled query and materialized views are the closest thing to it but still not the same.
"U can test ur queries in bigquery fastly in the console" seems like a great software engineering practice 😏 (it doesn't work over time if you don't just do POCs)
Views won't protect you if you change a field in upstream table while sqlmesh can by evaluating the SQL.
Yes you can throw yet another tool like sqllineage but it won't be integrated with terraform so it's not helpful.
I don't get your point: yes, nothing forces you to use sqlmesh nor dbt. projects on data engineering didn't start with their creation but they helped a lot improving developer productivity and applying best software engineering practices.