
Past years data engineering and current trends (2025 edition - Part 2)
This is part 2 of a multi-part series on current trends in data engineering and analytics in 2025.

You may find part 1 here: link to part 1.
In this part, I’ll cover another batch of 6 trends.
While writing this article, I learned a lot on these topics that this article is barely scratching. Hopefully you’ll learn some too! If you’re still wondering, yes, I’m AI assisted for writing (but I reviewed the whole content and some parts are handwritten).
So I think it’s worth a read 🙌
7. SaaS Data stack & Data Stack Templates

7.1 What are SaaS Data stack & Data stack templates
A SaaS Data Stack, is often related to the Modern Data Stack (MDS). It is a suite of integrated, cloud-based tools that organizations use to collect, store, clean, transform, and analyze data. Unlike traditional on-premises systems, a modern stack is expected to be modular, allowing companies to choose the best “best-of-breed” tools for each stage of the data lifecycle, from ingestion to visualization. These tools are typically offered as Software-as-a-Service (SaaS).
Data stack templates are opinionated, pre-configured setups that bundle these tools and best practices into a deployable package for common use cases or industries. They act as “starter kits” or scaffolds, providing a well-architected foundation for a data platform without the rigidity of a fully managed, all-in-one solution. Just like SaaS data stacks, these templates often include components for data ingestion, storage, transformation, testing, and visualization, with production-ready defaults.
7.2 Why it matters
The modern data landscape, with its vast array of open-source and commercial tools, presents a paradox of choice that can be overwhelming, especially for teams just getting started. SaaS data stacks and templates matter because they address this complexity directly:
Reduces Decision Fatigue and Speeds Time to Value: Templates provide a curated set of compatible tools, reducing the “analysis paralysis” of choosing from hundreds of options. This dramatically accelerates the initial setup, allowing teams to generate insights in days or hours instead of months.
Lowers Operational Overhead: By using managed SaaS tools, companies offload the burden of infrastructure maintenance, updates, and reliability to the vendor. This frees up expensive data engineering talent to focus on strategic initiatives that create business value, rather than just “keeping the lights on”. This shift leads to significant, quantifiable cost savings.
Embeds Best Practices and Governance: Templates codify best practices for data architecture, transformation, and security. They often include built-in features for data governance, quality, and observability, which are critical for building trust in data but are often overlooked in DIY setups.
7.3 Examples
Boring Data – Opinionated modern stack patterns template to build an AWS based data stack focusing on open source and efficiency.
Y42 – Fully managed end-to-end stack (ingest, transform, visualize) with governance baked in.
datacoves – Opinionated data platform combining dbt and Airflow.
7.4 Where it is heading
The future of the data stack is moving toward greater intelligence, specialization, and decentralization. Key trends include:
AI-Infused Stacks: Artificial intelligence is becoming a core operational component of the stack itself. This includes AI-assisted development to generate and optimize code, autonomous agents that monitor and remediate data quality issues, and natural language interfaces that allow any business user to query complex data by simply asking questions.
More alternatives: as those offers grow, we might expects that they could offer different compute engines, orchestration tools (e.g. Dagster vs Airflow) or transformation layer (e.g. dbt vs SQLMesh). They might even offer a full Apache Foudation projects based data stack at some point as there’s always a risk with licensing in the long run (will dbt Core survive dbt Fusion in the long run?).
8. GPU Powered Analytics & ARM Optimized Platforms

8.1 What is GPU powered analytics & ARM optimized platforms
Data platforms have historically been built on x86-64 CPUs, a CISC (Complex Instruction Set Computing) architecture known for its versatility and high single-threaded performance. However, two alternative architectures are fundamentally reshaping the data landscape: ARM and GPUs.
ARM (Advanced RISC Machines): This is a RISC (Reduced Instruction Set Computing) architecture. Unlike the “do-it-all” Swiss Army knife approach of CISC, RISC processors use a simpler, more streamlined set of instructions. This design leads to significantly lower power consumption and heat output, making them exceptionally efficient for scale-out workloads. Thanks to a mature ecosystem of compatible compilers and virtual machines (like the JVM for ARM), most modern data tools now run seamlessly on ARM-based systems like AWS Graviton and Google Cloud Axion.
GPUs (Graphics Processing Units): These are highly specialized processors with thousands of simpler, efficient cores. They operate on a SIMT (Single Instruction, Multiple Threads) model, which is a variation of SIMD (Single Instruction, Multiple Data). Think of a CPU as a master chef who can perform complex tasks one by one very quickly, while a GPU is an army of line cooks all performing the same simple task (like chopping vegetables) simultaneously. This massive parallelism makes GPUs uniquely suited for tasks involving large matrix operations, which are at the heart of machine learning, vector processing, and large-scale SQL aggregations.
8.2 Why it matters
The two primary drivers for adopting these architectures are Total Cost of Ownership (TCO) and raw performance. The choice is no longer just about speed, but about achieving the best price-performance for a given workload (and you’re probably aware of this if you’ve been working at a company spending millions on data infrastructure).
For ARM, the evidence is compelling. Cloud providers consistently report significant cost savings and efficiency gains.
Price-Performance: AWS claims its Graviton3 processors provide up to 40% better price-performance over comparable x86-based instances.
Real-World TCO: A case study by Aerospike showed that migrating their real-time database workloads to Graviton resulted in a 27% lower annual cost for their customers while delivering 18% higher throughput.
For GPUs, the performance gains on the right workloads can be staggering, but the calculus is more complex. The key insight is that simply “offloading” parts of a CPU-centric application to a GPU often fails to deliver promised gains due to data transfer bottlenecks over the PCIe bus. The most significant breakthroughs come from GPU-native systems built from the ground up.
GPU-Native vs. CPU-First: Voltron Data’s benchmarks on TPC-H queries revealed that a GPU-native engine like Theseus delivered a 10x cost/performance advantage over Spark-RAPIDS, an architecture that retrofits GPU acceleration onto a CPU-first framework. The analysis shows that for Spark-RAPIDS, the system becomes bottlenecked by the CPU’s ability to schedule tasks and move data, not by the GPU’s computational power.
8.3 Examples
GPU Powered Analytics
SQReam – A mature data warehouse designed for massive-scale analytics on GPUs, often used for petabyte-scale datasets.
Theseus – A new-generation, GPU-native query engine designed to overcome the bottlenecks of CPU-first systems like Spark. It demonstrates the potential of building analytics systems specifically for the GPU architecture.
RAPIDS – A suite of open-source software libraries from NVIDIA for executing end-to-end data science and analytics pipelines entirely on GPUs. Its core components, like cuDF and cuML, provide GPU-accelerated equivalents of the popular pandas and Scikit-learn APIs.
BlazingSQL (Historical Context) – Originally a SQL engine built on RAPIDS. The company officially shut down in 2-3 years ago and its core team joined Voltron Data. It was a key early player, and its work has been influential in the development of next-generation systems like Theseus.
ARM Optimized Platforms
Amazon Graviton – AWS’s custom ARM-based CPUs (now in their 3rd generation) that offer significant price-performance benefits across a wide range of services, including EC2, Lambda, RDS, and EKS.
Google Cloud Axion – Google’s custom ARM-based CPU for the data center, designed to offer industry-leading performance and energy efficiency.
Snowflake on ARM – Snowflake has made some of its virtual warehouse tiers available on ARM (specifically AWS Graviton), allowing customers to take advantage of the price-performance benefits for their data warehousing workloads.
8.4 Where it is heading
ARM has crossed the chasm. It is a mature, mainstream option for cloud data workloads, and its market share will likely continue to grow as organizations prioritize TCO and energy efficiency.
GPUs are the new frontier, but the ecosystem is in a state of flux. The primary trend is a move away from simply “accelerating” CPU-bound tasks towards building GPU-native and hybrid execution engines. This is not a solved problem, but it’s where the most innovative work is happening. The core challenge is building an intelligent workload classifier and scheduler. Modern research focuses on using machine learning models to predict whether a given query (or part of a query) will run more efficiently on a CPU or a GPU, factoring in both the computational complexity and the cost of moving data between system memory (RAM) and GPU memory (HBM).
Hardware innovations like NVIDIA’s NVLink and software APIs like GPUDirect Storage are helping to mitigate the traditional PCIe data bottleneck, making these hybrid systems more feasible.
Finally, the ecosystem is facing a potential turning point. NVIDIA’s CUDA platform is the undisputed leader, with a mature software stack and massive developer mindshare. This creates a powerful “moat” and vendor lock-in. However, the industry is pushing for alternatives:
AMD’s ROCm & HIP: AMD’s open-source ROCm platform and its HIP API (which allows for writing portable code that runs on both NVIDIA and AMD GPUs) are the primary challengers. While the hardware (like the MI300X GPU) is competitive on paper, the software ecosystem and community adoption still lag significantly behind CUDA.
Intel’s oneAPI: Intel is also promoting an open, cross-architecture programming model with oneAPI, aiming to break down the silos between CPUs, GPUs, and other accelerators.
The next few years will be a battleground. While CUDA’s dominance is unlikely to fade overnight, the growing demand for cost-effective alternatives and open standards will fuel the growth of ROCm and oneAPI, especially as vector databases and AI/ML workloads become standard components of modern data pipelines.
On a personal note, I am expecting a N5 Pro NAS to toy with local models and ROCm based experiments in the next weeks. I’m pretty curious how far we can get with local inference NPU (but it’s yet another topic).
9. One Interface – Multiple Engines

9.1 What is unified multi-engine routing
Unified multi-engine routing is an architectural pattern where a single, intelligent interface receives a user’s query and directs it to the most appropriate backend data engine for execution. Think of it as a smart logistics dispatcher for data queries. Instead of a user needing to know whether their question is best answered by a data warehouse, a vector database, or a streaming engine, a sophisticated routing layer makes that decision for them.
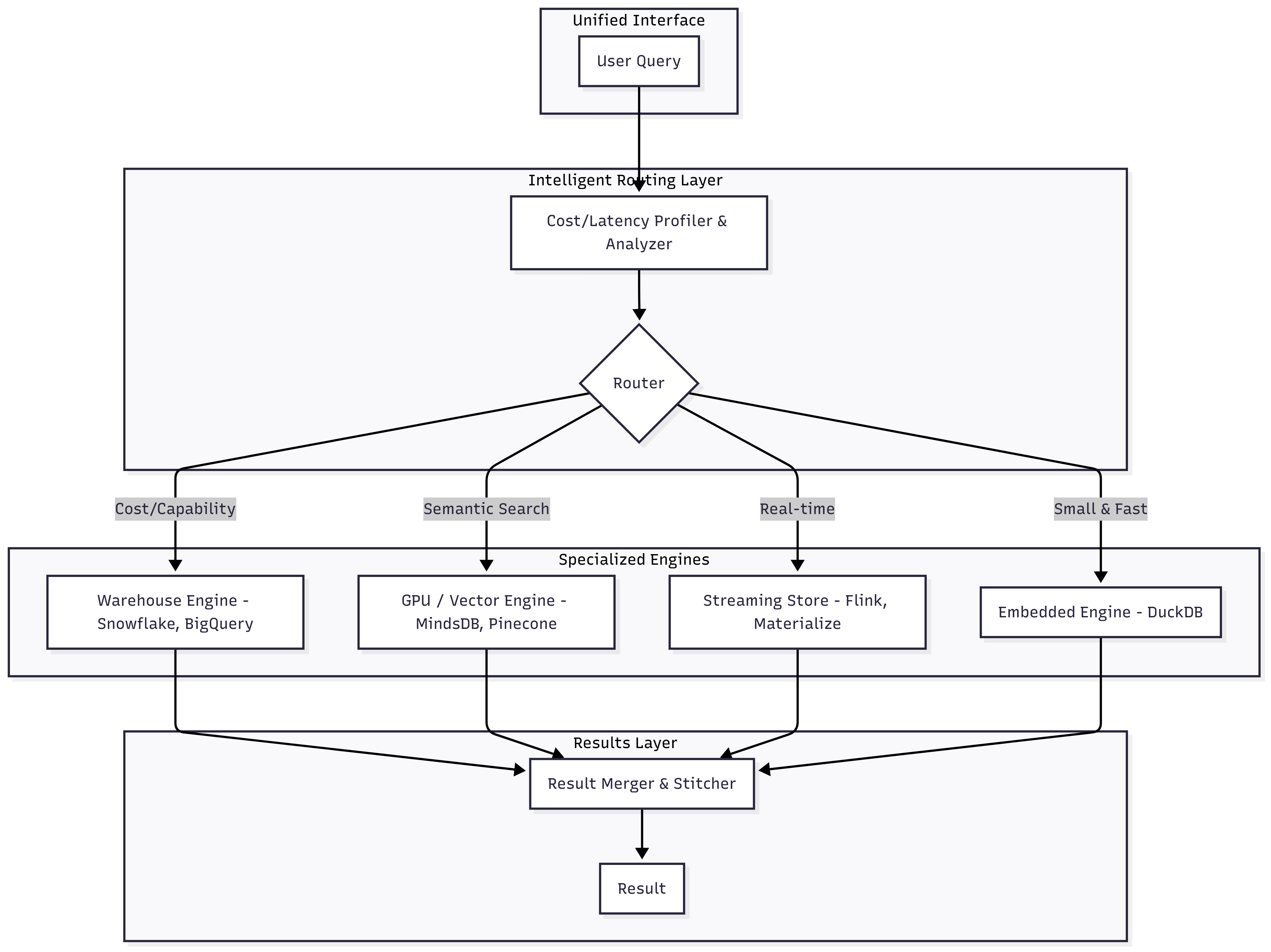
9.2 Why it matters
This approach fundamentally changes the user and administrator experience, moving from a fragmented collection of tools to a cohesive, intelligent platform.
For the User (Data Engineer/Analyst/Scientist): It provides a “best-of-breed” experience without the complexity. You can stream data to a table and join the results against historical data in a warehouse within a single SQL query. This dramatically reduces the cognitive load of tool-switching and data movement.
For the Business: It allows for optimizing cost and performance simultaneously. A small, interactive query can be routed to a fast, inexpensive in-process engine like DuckDB, while a massive, complex analytical job can be sent to a scalable cloud warehouse like Snowflake or BigQuery. This prevents over-provisioning and ensures resources are used efficiently.
For the Administrator (Data Platform Engineer): It centralizes governance, security, and monitoring. Instead of managing access and observability across a dozen different systems, you manage it at the routing layer. This architecture also future-proofs the data stack; a new, faster engine (e.g., a GPU accelerator) can be added to the backend without disrupting a single user workflow. The key technical enabler for consistency in these setups is the adoption of open table formats (see next section), which allow multiple engines to safely read and write to the same underlying data.
9.3 Examples
This pattern is emerging in both commercial platforms and open-source projects:
Deltastream – A “streaming-first” serverless database. Its Fusion architecture automatically chooses the most efficient engine—Flink (for streaming), Spark (for batch), or ClickHouse (for interactive)—for each workload, all behind a unified SQL interface.
Greybeam – A platform that intelligently routes queries between DuckDB and Snowflake. It uses heuristics (table size, query plan) to run smaller queries on a local DuckDB instance and larger ones on Snowflake, minimizing warehouse costs.
DuckDB in PostgreSQL – A practical example of hybrid execution. This extension allows PostgreSQL to offload analytical query processing to DuckDB, combining a world-class transactional engine with a best-in-class analytical engine in a single system.
9.4 Where it is heading
The Mooncake team was right when they declared that “HTAP might be dead.” The dream of a single database that perfectly handles both transactional (OLTP) and analytical (OLAP) workloads has proven technically and organizationally difficult. However, the need for HTAP—real-time analytics on fresh, operational data—hasn’t disappeared. It’s being resurrected in this disaggregated, multi-engine form.
The future of this trend is focused on making the routing layer increasingly intelligent and dynamic:
AI-Powered Predictive Routing: The “analyzer” will evolve from simple rule-based heuristics to sophisticated machine learning models. These models will predict the cost and latency of a query on each available engine before execution, using historical performance data to make the optimal choice based on user-defined SLAs.
Adaptive, Mid-Flight Optimization: Drawing inspiration from concepts like Adaptive Query Execution (AQE) in Spark, systems will not only choose the best engine upfront but also adjust execution plans dynamically. If a query part is taking longer than expected, the router could re-optimize and shift the remaining work to a different engine mid-flight.
Fully Partitioned Query Plans: A single complex query will be deconstructed into a directed acyclic graph (DAG). The router will execute parts of this graph on entirely different systems simultaneously—for example, performing a vector search on a GPU, filtering a real-time feed in a streaming store, and joining the results against a historical archive in a data warehouse. The “Merger” component will become a highly sophisticated coordinator responsible for combining these heterogeneous results.
10. Open Table Format Everywhere

10.1 What is open table format
Open table formats have becoming a standard for data storages in pretty short amount of time. They brought a lot of capabilities to data lakes that were previously only available in data warehouses. For instance, the biggest players (Apache Iceberg, Delta Lake, and Apache Hudi) bring ACID transactions, schema evolution, time travel, manifest metadata to object stores so multiple engines can cooperate without file stomping.
Iceberg, Delta, Hudi (and friends) bring ACID transactions, schema evolution, time travel, manifest metadata to object stores so multiple engines can cooperate without file stomping.
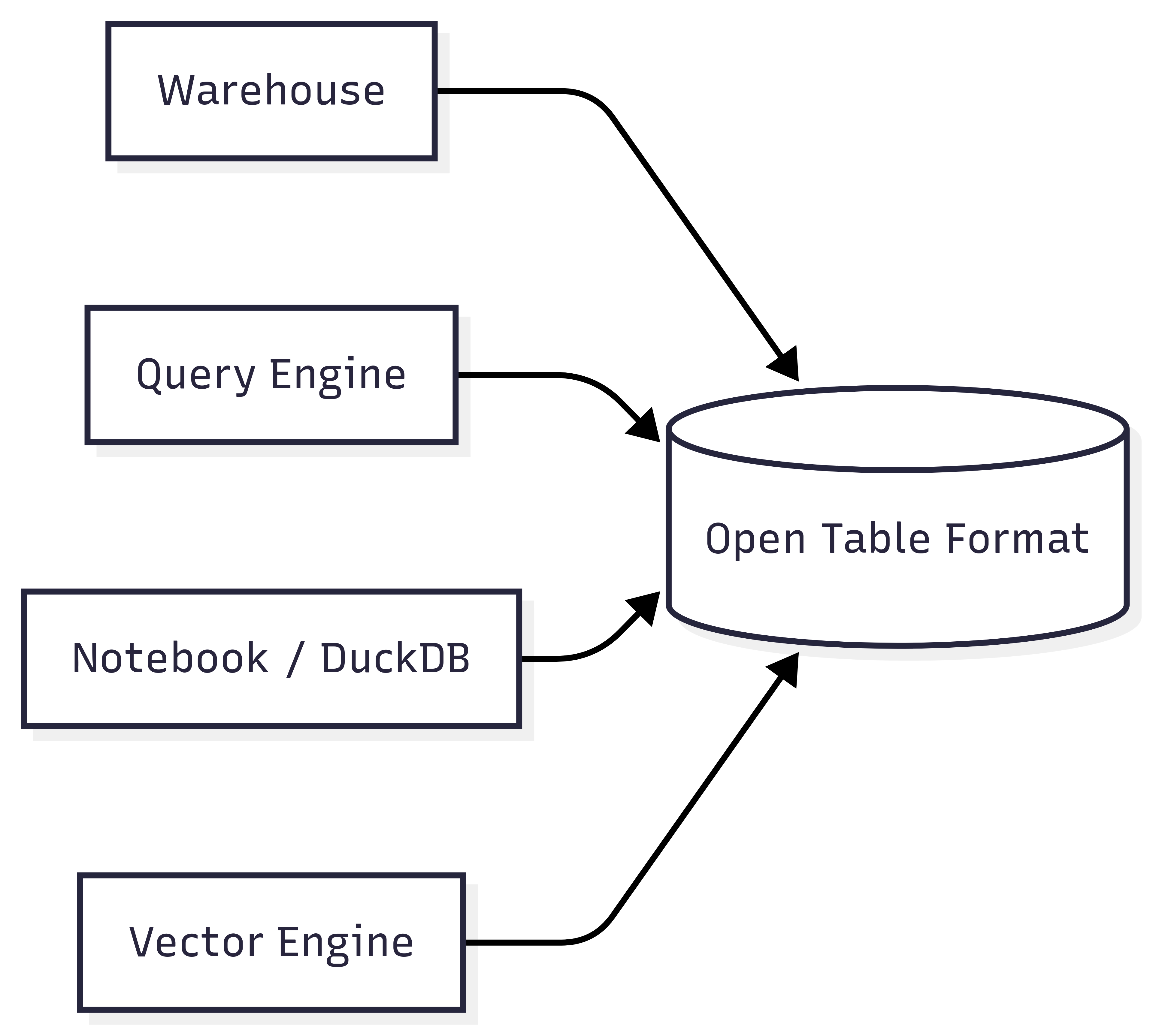
10.2 Why it matters
They’re the neutral backbone that keeps you from locking into one compute vendor. Open formats encourage multi-engine experimentation (e.g., run incremental jobs in Spark, serve with DuckDB, explore with Trino) without reshaping data every time.
10.3 Examples
Apache Iceberg – Partition + metadata evolution friendly table format with hidden partitioning and snapshots.
Delta Lake – Transaction log driven format enabling ACID & time travel on lakes.
Apache Hudi – Incremental ingest + upserts + change capture optimized table layer.
DuckLake – DuckDB integration story for engaging with lake formats (emerging work).
10.4 Where it is heading
Native Support Becomes Ubiquitous: All major engines will offer first-class, native support for at least one open table format (e.g., Snowflake or BigQuery with Iceberg), making them a default choice rather than an add-on.
Standardized Governance: The format layer will become the center of gravity for data governance. Core functions like access control, data quality enforcement, and lineage tracking will be defined directly on the tables themselves. Iceberg’s v3 specification for row-level lineage is a clear indicator of this trend.
Git-Inspired Metadata Operations: Metadata features inspired by Git, such as branching, tagging, and multi-table transactions, will become standard. Iceberg’s support for branching and tagging in its v2 spec, combined with catalogs like Nessie that enable atomic, multi-table commits, are making data management more robust and auditable.
Metadata-Driven Query Optimization: Engines will increasingly use rich format metadata for adaptive query optimization. By leveraging detailed statistics, partition information, and indexes (like bloom filters or vector indexes), engines can dramatically accelerate queries through intelligent data pruning and skipping.
The “Metadata Database” Emerges: The metadata layer of an open table format may evolve into a lightweight, queryable database in its own right. The DuckLake concept, which integrates DuckDB’s query capabilities directly with the format’s metadata, exemplifies this. While centralizing metadata offers benefits, it also raises new architectural questions, such as how to maintain transactional consistency across multiple, decentralized “metadata databases” within a single organization.
11. Next Generation Storage Formats

11.1 What is next generation storage formats
Parquet is the de facto standard for columnar storage in data lakes, but new formats are emerging to address its limitations and add new capabilities. These next-generation storage formats, like Lance and Vortex, are not just incremental improvements; they represent a fundamental redesign of how data is stored and accessed.
They move beyond the concept of a static file format to become a more comprehensive data toolkit. They are built from the ground up for the demands of modern AI/ML workloads, prioritizing extremely fast random access, native support for complex data types like vectors, and tight integration with data versioning and query engines. Unlike Parquet, which was optimized for sequential scans over large datasets (OLAP), these new formats are designed for the iterative, “needle-in-a-haystack” access patterns common in machine learning.
11.2 Why it matters
The shift to new storage formats matters because the nature of data and its use cases have evolved dramatically. The rise of AI, vector databases, and large language models (LLMs) has created new bottlenecks:
Performance for AI/ML: Traditional formats are too slow for ML workflows. Training models on specific data slices, running vector similarity searches for RAG, and interactively exploring data all require microsecond-level access to specific rows, which Parquet was not designed for.
Unified Data Management: AI workloads often involve diverse data types (images, text, audio, vectors, tabular data). Next-gen formats aim to store raw data and its vector embeddings together, eliminating the need for complex joins between a columnar store and a separate vector database.
Efficiency and Cost: By enabling faster queries, better compression for modern hardware, and features like “compute pushdown” (performing calculations on compressed data), these formats reduce infrastructure costs and speed up the entire data-to-insight pipeline.
Reproducibility: Built-in, zero-copy data versioning (as seen in Lance) is critical for ML experiment tracking, model debugging, and governance, making it trivial to query a dataset as it existed at a specific point in time without duplicating storage.
11.3 Examples
Parquet – The current industry-standard columnar format, optimized for high compression and efficient, sequential scans in large-scale analytical (OLAP) workloads.
Lance – A modern columnar format designed for AI, featuring extremely fast random access, zero-copy versioning, and native storage for both raw data and vector indexes.
Nimble – An experimental, read-only columnar format from Meta focused on achieving extremely high compression ratios to enable faster scans on massive, static datasets.
Vortex – A highly extensible columnar format built for modern hardware (NVMe, GPUs) that uses a “compute pushdown” model and allows new encodings via WebAssembly to accelerate real-time analytics.
F3 - A new format attempting to address the layout shortcomings from Parquet while at the same time maintaining good interoperability and extensibility (a.k.a future-proof) via embedded Wasm decoders (feels like close to Vortex).
11.4 Where it is heading
The future of data storage formats is moving towards a more intelligent and integrated data layer. The key trends are:
Convergence of Data and Indexes: Formats will no longer just store data; they will natively manage rich secondary indexes (vector, search, etc.) within the same file, treating data and its indexes as a single unit.
Storage-Compute Integration: The boundary between storage and query engines will blur. Formats will become more active, with capabilities like compute pushdown and embedded kernels (e.g., Vortex’s WASM) allowing computations to happen directly on the compressed data, minimizing data movement.
AI-Native by Default: Support for vectors and multimodal data will become a standard feature, not an exception. Formats will be designed with the entire ML lifecycle—from data prep and training to inference and versioning—in mind.
Increased Extensibility: To avoid the rigidity of past formats, future designs will be more modular and extensible, allowing them to adapt to new hardware and compression schemes without requiring a complete ecosystem overhaul.
12. AI Functions in databases & Data Warehouses

12.1 What is AI functions in databases & Data Warehouses
AI functions represent a paradigm shift, transforming the data warehouse from a passive repository into an active intelligence engine. Instead of exporting data to external machine learning platforms, these functions allow you to perform AI/ML tasks directly where the data lives.
At their core, they are a set of built-in primitives that handle the entire ML lifecycle within the database’s native environment. This includes:
Predictive Modeling: Training, evaluating, and deploying classical machine learning models (like regression, classification, and time-series forecasting) using familiar SQL or Python APIs.
Vector Embeddings & Search: Creating and indexing vector embeddings from your structured and unstructured data, enabling semantic search, similarity matching, and Retrieval-Augmented Generation (RAG) for LLM applications.
Inference & Scoring: Running predictions by calling a deployed model (either trained in-database or externally) as a simple function on new data, whether in batches or on real-time streams.
Generative AI Integration: Calling external Large Language Model (LLM) endpoints (like OpenAI or Anthropic) directly from SQL, allowing you to enrich your data with sentiment analysis, summarization, or classification without complex pipeline orchestration.
Syntetic Data Generation: Generating synthetic datasets for testing, augmentation, or privacy-preserving analytics using built-in generative models.
This co-location of data, feature engineering, and AI computation fundamentally simplifies the MLOps lifecycle.
12.2 Why it matters
Moving computation to the data, rather than data to the computation, delivers quantifiable benefits in speed, cost, and security.
Better Data Freshness: Shipping large datasets out of the warehouse introduces significant delays. For use cases like real-time fraud detection or instant personalization, this latency is unacceptable. In-database scoring can operate within strict time budgets (e.g., under 50 milliseconds for a fraud check), which is impossible with traditional ETL-based ML pipelines.
Lower Costs: Cloud egress fees, charged for moving data out of a provider’s network, can be substantial, often ranging from $0.02 to $0.09 per gigabyte. By eliminating this data movement, you cut direct costs. Furthermore, consolidating workloads reduces infrastructure sprawl. A WHOOP case study using Snowflake’s Snowpark, for instance, saved over 20 hours of compute per day by eliminating the need for separate system.
Strengthened Governance & Simplicity: Keeping data within the warehouse’s security perimeter drastically reduces the risk of data leaks or compliance breaches. It also simplifies pipelines. A case study with Scene+, a Canadian loyalty program, found that using in-database ML reduced the time-to-production for models by 60% and cut costs by over 35% by simplifying their MLOps stack.
Democratization of AI: By exposing ML capabilities through familiar SQL syntax (e.g.,
CREATE MODEL), this approach empowers a much wider audience of data analysts and analytics engineers to build and deploy predictive models, lowering the barrier to entry that often exists with specialized data science platforms.
12.3 Examples
The landscape for in-database AI is mature and competitive, with each major platform offering a unique approach.
Snowflake: Uses its integrated Snowpark compute to run Python, Java, and Scala, targeting data teams who need a blend of SQL and Python for ML model deployment without extra infrastructure.
BigQuery ML: Trains models natively with SQL
CREATE MODELstatements, making it highly accessible for SQL analysts and data scientists who prefer a declarative, abstracted approach.Databricks: Leverages its unified Spark and Delta Lake engine, offering maximum flexibility for data scientists and ML engineers through deep Python/R integration and powerful SQL.
Amazon Redshift ML: Integrates with SageMaker for model training, sending data out and importing the trained model back as a function. Best for AWS-centric teams wanting to use SageMaker’s power without managing the pipeline.
SingleStore: A real-time hybrid engine with built-in vector functions, designed for low-latency applications like fraud detection on live, streaming data.
Postgres + pgvector: An extensible, open-source RDBMS with vector similarity search, offering a cost-effective and flexible solution for developers building AI features into applications.
12.4 Where it is heading
The future of the data warehouse is as a lightweight, intelligent feature and model factory, not just a passive data store. Key trends are pushing this evolution:
Fused Registries and Lineage: Expect to see deep, automatic integration between model registries and data lineage. You’ll be able to instantly see which version of a model was trained on which version of a feature table, track feature importance over time, and trigger automatic retraining when upstream data drifts.
Cost & Performance Observability: Platforms will provide fine-grained tracking of model performance, data drift, and the compute cost of both training and inference. This will allow for more sophisticated MLOps, like automatically disabling costly, underperforming models.
Conversational Data Interaction: As LLMs become more integrated, analysts will increasingly interact with the warehouse through natural language, asking it to not only query data but also to “build a model to predict customer churn using these tables” or “explain why this model’s accuracy has dropped.” The warehouse becomes an active partner in the analytical process.
GPU Acceleration: While current in-database ML solutions are CPU-bound, the next generation will integrate GPU acceleration, either through hybrid architectures (like Snowflake’s support for external GPU clusters) or by building GPU-native query engines that can handle both SQL and ML workloads seamlessly.
Conclusion
The data engineering landscape of 2025 is clearly coalescing around an intelligent, cost-aware, and composable stack. From the silicon to the storage formats, every layer is being optimized to deliver insights faster and more efficiently.
But this smarter foundation is just the beginning. The very definitions of “database,” “pipeline,” and “data platform” are starting to blur. What happens when your database can run AI models and host entire applications? When streaming data behaves just like a SQL table? And when computation moves from the centralized cloud to the very edge where data is created?
In the third part of this series, we’ll explore these disruptive shifts—from federated queries to the rise of edge computing and SQL over streaming—and examine how they are forging a new, more dynamic paradigm for the world of data. Stay tuned.
🎁 If this article was of interest, you might want to have a look at BQ Booster, a platform I’m building to help BigQuery users improve their day-to-day.
Also I’m building a dbt package dbt-bigquery-monitoring to help tracking compute & storage costs across your GCP projects and identify your biggest consumers and opportunity for cost reductions. Feel free to give it a go!
Few months ago, we released a dbt adapter for Deltastream, a cloud streaming SQL engine. If you're interested in combining the power of dbt with real-time analytics capabilities, I'd love to chat about it.