
Past years data engineering and current trends (2025 edition - Part 1)

This is the follow-up to the list I drafted early 2024 (see the original reflection piece: 2024 data engineering trend retrospective). I planned to write on all the topics of this article last year but I couldn't find the time to write about it. A year (and half) is pretty short yet long enough in data tooling for a trend to go boom or bust.
In this part, I cover 6 trends. I've more to come in future parts: I’ve currently 15 more topics to share in my drafts! Hopefully I’ll be pushing next one before next year…
1. Caching Layers
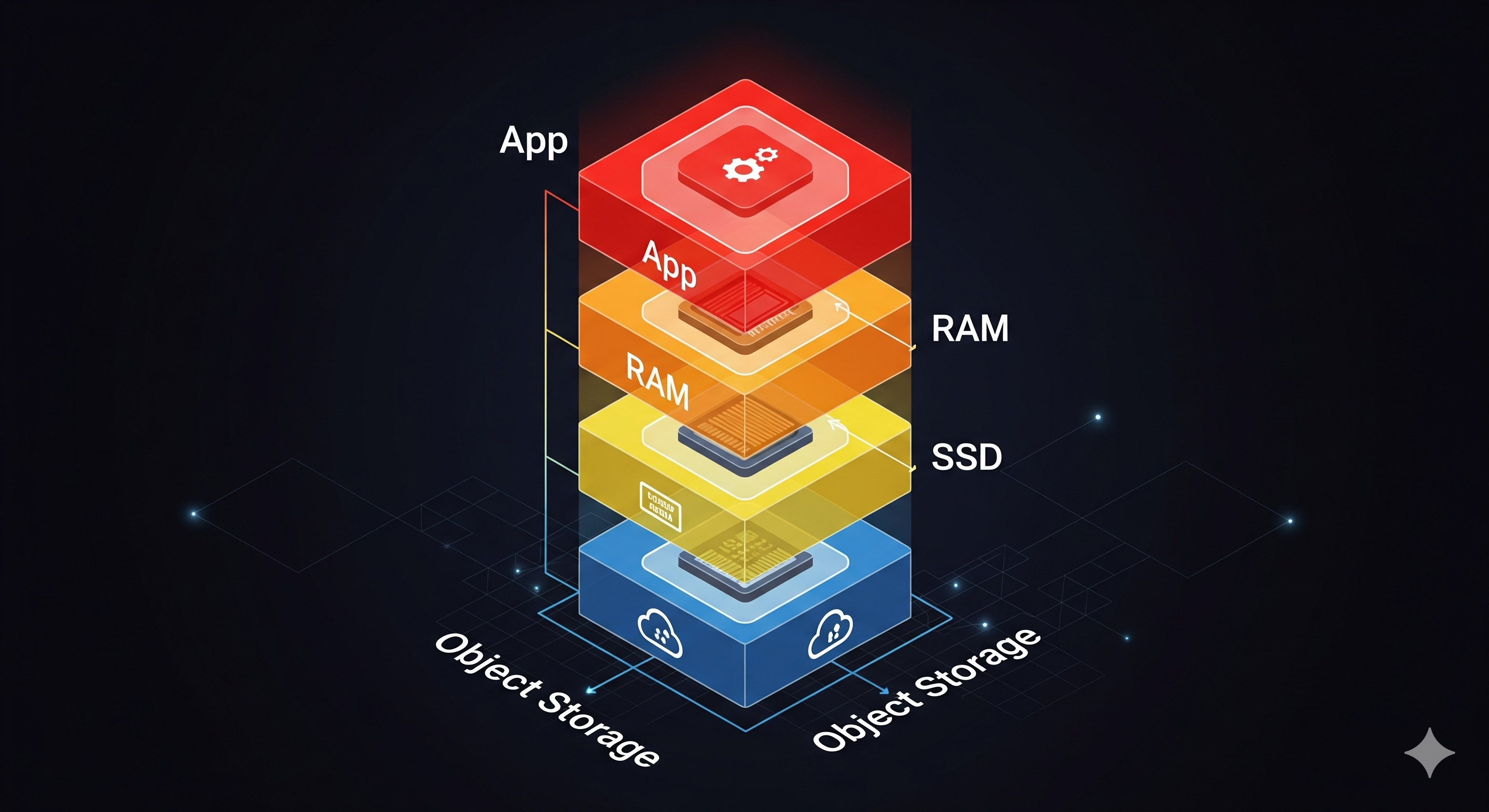
What is a caching layer
It’s the “don’t hit the giant warehouse every single time” layer. Here's some of the techniques involved: pre-aggregations, materialized views, hot columnar fragments in RAM, vectorized result reuse, multi-tier stores (RAM → SSD → object storage).
Why it matters
Users expect interactive dashboards that feel like live apps, not batch reports. Re‑scanning cold Parquet for every filter change is wasteful when the hot working set might compress to a few hundred GB and sit comfortably in memory. Memory is ~4× faster than SSD and ~40× faster than spinning disk (rough approximation).
Good caching saves latency and cuts cost because you stop paying for CPUs idle‑waiting on storage.
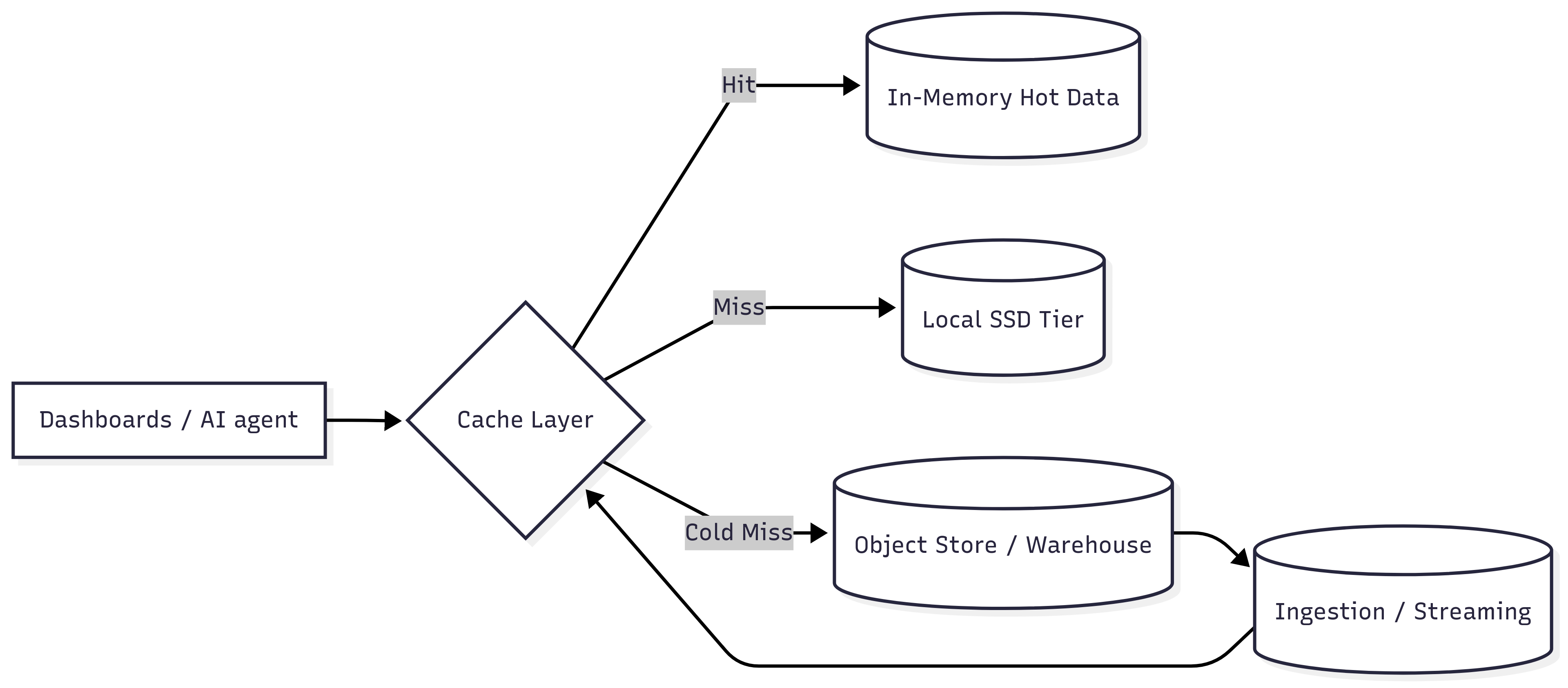
Examples
Apache Druid – Real-time OLAP store with segment + query result caching to slash repeated scans.
Cube – Semantic + pre‑aggregation service that builds and serves aggregate cubes.
Indexima – In‑memory acceleration layer using smart indexing + compressed column storage.
BigQuery BI Engine – Managed in‑memory accelerator that keeps hot slices near the CPU for sub‑second BI queries.
MotherDuck + DuckDB – Hybrid local/cloud DuckDB that can act as an embedded analytical cache in front of lakes/warehouses.
Where it is heading
We’ll keep collapsing “hot analytical working sets” into a memory-first zone: embedded DuckDB processes, Arrow buffers glued to apps, vector caches that also serve embeddings. With AI progresses, we'll see more "automatic promotion": systems learning which partitions, joins, or metrics deserve to be hydrated. Instead of a dry “universal in‑memory accelerator” pitch, think: a self-tuning layer that quietly keeps your most important data warm while pruning less relevant data (think it like a smart LFU caching).
2. Semantic Layers
What is a semantic layer
It’s the canonical dictionary of metrics, dimensions, and business logic exposed via SQL, APIs, or a modeling DSL. If you want everyone to mean the same thing when they say “total revenue” or “active customer,” this is the layer.
Why it matters
Without it, every Looker/Mode/ recreates “revenue” slightly differently leading to inevitable confusion across teams. As LLMs generate more queries, semantic layers are becoming a requirement to produce accurate and consistent results otherwise… you’re going to get an explosion of subtly wrong metrics. A good semantic layer is both a contract and a guardrail.
Examples
dbt Semantic Layer – Central metrics definitions exposed through adapters + consistent compile layer. It is powered by MetricFlow.
Cube – API-first modeling + caching + access control for metrics across apps.
Looker (LookML) – Mature DSL for explores, governed joins, reusable measures.
AtScale – Enterprise semantic virtualization + aggregation + governance.
Where it is heading
We’ll see “assistive modeling”: tools suggest draft metrics from query logs, flag orphaned dimensions or detect accidental redefinitions. Expect semantic layers to feed AI agents a structured schema/metric graph so generated analyses stop hallucinating. I’m hoping we see semantic layer getting more integrated with jobs, services and inhouse APIs: the SQL endpoint middleware approach is definitely one I like (Cube has one). Then Repo-backed vs SaaS? Probably both: code for versioned logic + a runtime that watches real queries to surface drift.
3. Interoperability & Optimization Layers
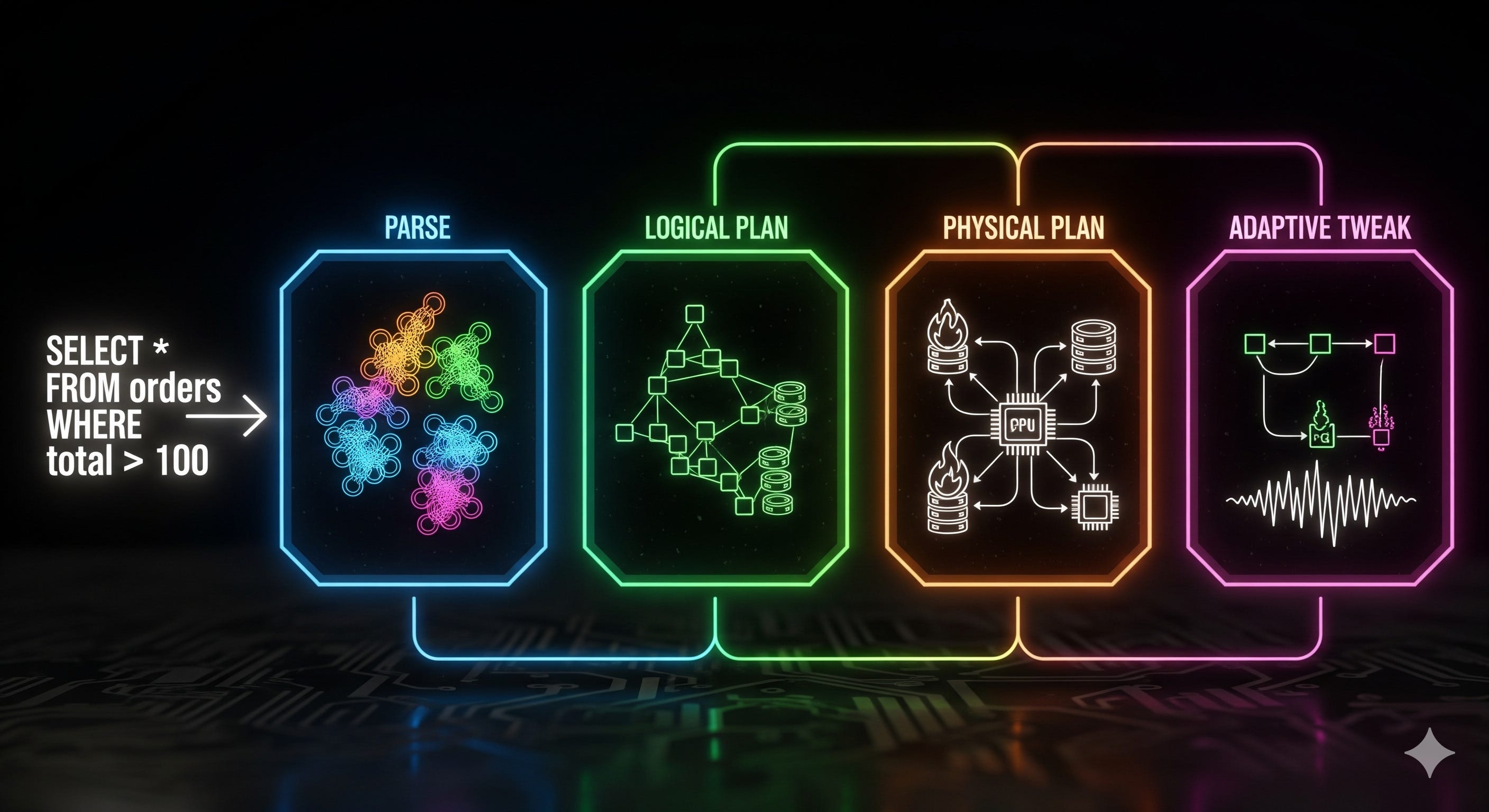
What is an interoperability & optimization layer
It’s the brain that rewrites your queries before (and sometimes during) execution: cost models, join reordering, predicate pushdown, vectorization choices or even engine routing (we’ll get back to this one later). Calcite, Substrait, DataFusion, or custom planners inside warehouses all fit here. The goal: decouple what you want from how it gets done.
I’ve talked about interoperability and standardized compute plan in my previous article and I think that this layer is tightly linked to these topics.
Why it matters
A portable optimization layer means fewer bespoke rewrites and smarter decisions. It’s performance and cost control through plan intelligence. They are reusable across engines and will foster standards to build engines way more quickly than starting from scratch which could help democratize custom execution engines.
Examples
Apache Calcite – Embeddable cost + rule optimizer used in many SQL engines.
Substrait – Shared intermediate representation for portable query plans.
SQLGlot – Python SQL parser/rewriter + dialect translation + optimization passes.
DataFusion – Rust query engine with pluggable logical/physical optimizer stages.
Where it is heading
This is the area I know the least deeply, but one direction is clear: adaptive plans become normal: start executing, collect lightweight stats, pivot mid‑flight (switch join strategy, spill, or offload to GPU). We’re seeing strong investments in DataFusion through great projects like dbt Fusion, so I guess we’re still early.
4. Gen AI Powered Natural Language

What is Gen AI powered natural language
Conversational and “ask a question like a human” interfaces over catalogs, metrics, and datasets. It glues catalog metadata + lineage + semantic layer so users type “churn last quarter vs same quarter previous year” and get runnable SQL (or even a chart) without any prior knowledge.
Why it matters
Most people in a company will never learn warehouse schemas: some product manager at my work can do a lot of SQL but they are not legion nor able to troubleshoot performance issues. NL (natural language) → SQL raises data access while reducing ad-hoc Slack pings to the data/analytics team. Pair it with catalog awareness and you also solve discovery: “We already have a table for that metric.” It’s the graal of self-serve analytics.
Examples
Snowflake Copilot – In‑interface assistant for query help, explanations, transformations.
Gemini in BigQuery – Google assistant for SQL authoring + guidance.
Databricks Assistant – Notebook + SQL workspace helper with context awareness.
Secoda – AI-enhanced catalog/search + natural language data exploration.
Where it is heading
The differentiator shifts from “can it generate SQL?” to “does it understand approved semantics, row-level policies, and cost budgets?”.
I think we could expect:
guardrails (explain plan before run, highlight costly ops)
tool-generated follow-up queries (“Want retention breakdown by segment?”).
multi-modal (upload a CSV or screenshot of a chart and ask questions about it)
tighter integration in BI tools (generate dashboards from a prompt)
5. Gen AI Oriented Automations

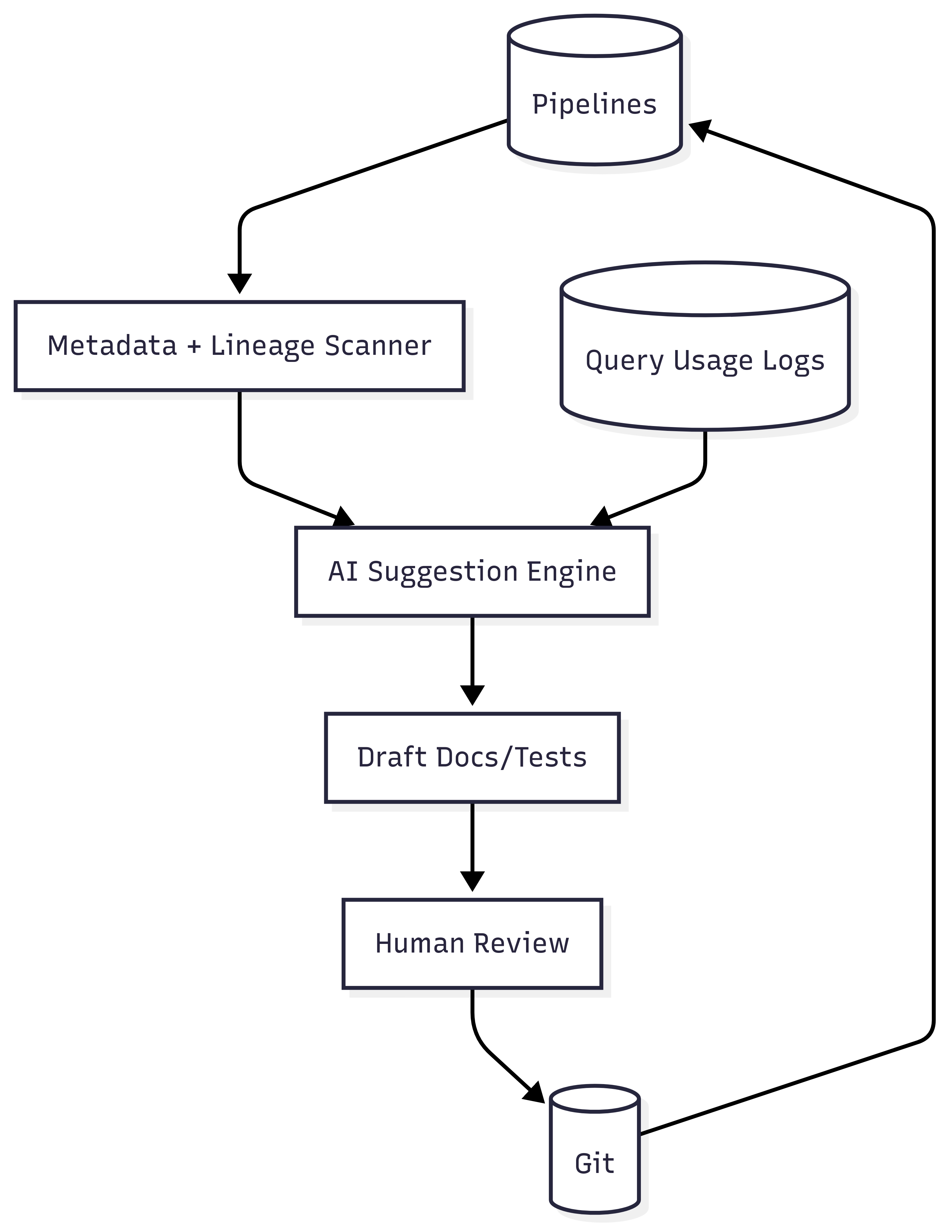
What is Gen AI oriented automations
AI isn’t just about answering questions; it’s also about doing things. AI agents can also scan projects and codebases to propose or auto-generate missing pieces: docs, quality tests, lineage annotations, sample data contracts, even refactor suggestions.
Why it matters
Analytics debt builds quietly: undocumented models, silent schema drift, out-of-date tests. AI reduces toil by drafting the 80% version of a test suite or doc page so humans can review instead of starting cold. Faster onboarding, fewer “tribal knowledge only” traps. It’s a game-changer to balance speed and quality in data teams.
Examples
Monte Carlo – Data observability with anomaly detection + incident context.
Great Expectations – Test framework now layering AI suggestions for expectations.
dbt Copilot – Inline model doc + test suggestion inside dbt workflows.
Metaplane – Automated metadata + anomaly/sensitivity detection.
Datafold – Diff + impact analysis with AI summarization.
Where it is heading
The shift is toward proactive assistants: “This dimension is never queried; want to deprecate?” or “Two models implement customer_ltv differently, should we merge them?” Eventually: dependency graph + semantic layer + usage stats feed a continuous “hygiene score.” Winners will produce explanations not just automatic changes. There’s so much to build here.
6. Ecosystem Consolidation and Vertical Integration
What is ecosystem consolidation and vertical integration
Over the last decade a flood of tools each tackled a slice of the stack. Now the pendulum swings back toward integrated platforms spanning ingestion, storage, transformation, governance, and serving. Hyperscalers did this early; now Snowflake, Databricks, and others expand aggressively. Capital is pricier (rates >> 2021) and VC dollars skew to AI infra, opening consolidation opportunities at lower valuations.
Vertical integration can also happen inside one platform: e.g. Google layering Datastream (CDC) and Iceberg support into BigQuery directly competing with a lot of companies.
Why it matters
Each integration you own is a mini product: auth, schemas, secret rotation, failure modes. As you add vendors, the complexity grows and the risk of integration issues increases. Also some open source tools/platforms might stale or startups may fail/pivot. Nowadays a lot of data platforms are core part of businesses, so that leadership may prefer safe choices with fewer moving parts. Finally, integrated platforms can optimize end-to-end performance and cost in ways that stitched-together stacks can’t.
Examples
dbt + Transform/SDF (acquisition) – Folding metric authoring into the dbt workflow for end‑to‑end modeling + metrics. Pushing dbt into an engine on its own.
BigQuery + Salesforce (native connectors) – Direct replication / sync pathways reducing custom ELT code.
Fivetran + SQLMesh (pipeline synergy) – Orchestrated ingestion + declarative transformations with testing.
Where it is heading
Data engineering infrastructure/tooling space is maturing. The next 5 years will see more platforms expanding their scope to cover multiple layers of the stack. We’ll still have modular purists (I’m somehow one of them 🤫), but the gravitational pull favors platforms that feel cohesive yet allow escape hatches (e.g. external tables or UDFs).
Next
As mentioned in the beginning, this part is just a piece of the series. I’m not sure what’s the timeline for the next part (it took me few hours to build this whole article).
Anyway, let me know if you’re interested in more of those kind of articles as I guess I might try to shard the parts to avoid "buffering".
Edit: The part 2 is now ready:
🎁 If this article was of interest, you might want to have a look at BQ Booster, a platform I’m building to help BigQuery users improve their day-to-day.
Also I’m building a dbt package dbt-bigquery-monitoring to help tracking compute & storage costs across your GCP projects and identify your biggest consumers and opportunity for cost reductions. Feel free to give it a go!
Few months ago, we released a dbt adapter for Deltastream, a cloud streaming SQL engine. If you're interested in combining the power of dbt with real-time analytics capabilities, I'd love to chat about it.
I can't believe I missed this one when it came out but loved this breakdown. Also great to find a fellow Gemini image creator : )
I agree with the hot analytical working sets take to keep data as close to the app as possible. There's a number of competing file formats I see being useful including the new "F3" which has WASM binaries to decode the data.
Very excited to see where the cache layer alone goes but all the other ones noted are well on their way.